

Making a large-scale cloud migration is a challenging task because you’ve issues like latency and security to look after. Chances are, you may have bandwidth that's slower than you'd like.
And when you’re trying to move a huge chunk of of data? It all adds up, making the process too complicated to be handled with ease.
It’s something that many businesses across the globe are doing because in general the world’s data is exploding. We’re talking about 100 zettabytes in cloud storage by 2025.
And you guessed it, much of that is being shuffled across hybrid cloud setups. Gartner says that by 2027, 90% of orgs will be juggling on-prem and cloud stacks.
It’s here you need the AWS Snowball which gives back control of your cloud data migration strategy. You will be able to cut time, lower cost, and actually make the process manageable.
There’s a real payoff involved in using AWS Snowball data migration — be it handling it for the first time or scaling an existing setup. You’re all set for faster turnaround, better security, and less dependency on flaky internet speeds.
On further reading, you’ll find out what Snowball actually does, where it shines in large-volume data migrations, and the AWS Snowball best practices we’ve seen work time and again.
What is AWS Snowball?
At macro-level AWS Snowball is physical data transport solution designed for secure, high-volume transfers to AWS without relying on internet bandwidth.

It has the capacity to move terabytes—or petabytes—of data securely and fast, without choking your network.
For example, you’ve to move 500 TB of logs, backups, or videos to push that over the web.
Think you need around weeks or months? Not really, with AWS Snowball.
Because, AWS Snowball for large data migrations will load your data locally, ship it to AWS, and you’ll have your data in your S3.
Key Components
Let’s break down a few major aspects involved in the AWS Snowball.
AWS Snowball Edge Storage Optimized
You get up to 80 TB usable storage which is good for big file transfers, and yes, it runs EC2 and Lambda.
AWS Snowball Edge Compute Optimized
You get the power of 52 vCPUs, NVIDIA Tesla V100 GPU (if needed) which is suitable for field deployments or edge analytics and you leverage it well with an additional AWS cloud computing services.
Snowball Client Software
Highly useful in managing transfers via AWS Snowball CLI or API. Your command center for file loading, encryption, and status checks.
Security & Compliance
This isn’t just about speed. It’s a secure data transfer solution too because of —
- 256-bit encryption baked into the hardware.
- Integrated with AWS KMS—no manual key juggling.
- Full chain-of-custody logs, which come in clutch for audits and compliance checks.
You can be eyeing for AWS Snowball Edge for hybrid setups or just need secure cloud data transfer, these layers are built-in.
How AWS Snowball Edge works?
There’s a reason AWS Snowball data migration is a go-to for enterprises moving terabytes and up. It’s a powerful device that;s built for scale, control, and visibility without letting your network take the hit.
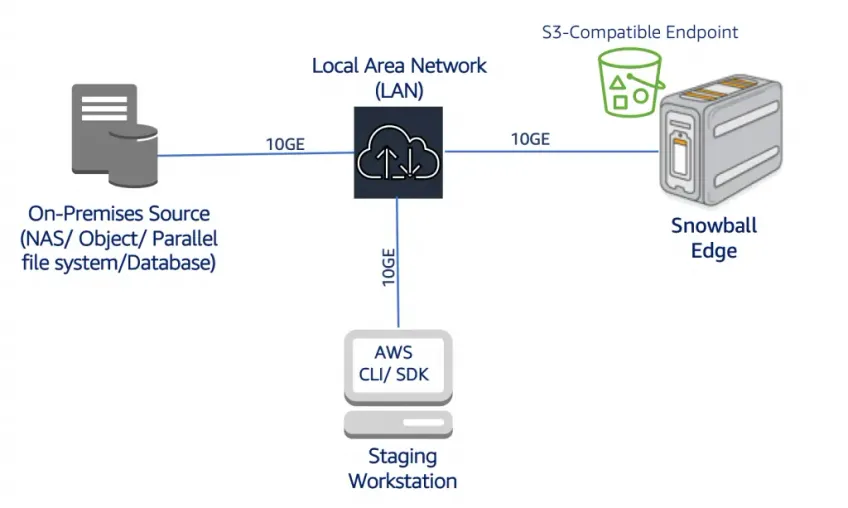
Let’s walk through how Snowball data transfer actually works:
Once the device hits your site, you plug it into your local setup.
Then use the Snowball client or CLI to load your files. Once it’s full, ship it back. AWS uploads everything straight to your target S3 bucket. Done.
You’ll be yielding the following benefits of AWS Snowball.
Bypasses bandwidth limits
Instead of clogging up your internet for weeks, you ship the data physically with the help of encryption and taking considerations for AWS cloud security service. It’s a perfect solution for large-volume data migrations that would choke traditional networks.
Reduces downtime in critical operations
Snowball comes with compute power so that you can start processing or transforming your data right there on the edge even before it even hits AWS. This is super-useful in industries where downtime can lead to revenue losses.
Secure, trackable transit
With encrypted enclosures and tamper alerts, you’ve got not just a fast but even a highly-secure cloud data transfer methods. Add real-time shipping tracking and KMS-backed key management for top-notch protection.
Supports hybrid workloads
Are you running IoT, remote workstations, or video surveillance ops? Well then, the Snowball lets you stage or preprocess data locally and send it to S3 when ready without the need to stay plugged into the internet 24/7.
Ideal for regulated industries
From HIPAA to GDPR and FedRAMP, AWS data migration doesn’t skip compliance. There are Snowball’s audit trails and encryption setup which help meet tight regulatory standards without additional efforts.
AWS Snowball pricing is usage-based but the the cost of AWS Snowball varies depending on region and job size. Generally, it is cheaper than long-haul online transfers.
More on that later.
Read more: Top 10 benefits of moving to AWS cloud for your business
10 Best practices of using AWS Snowball
When you're dealing with large-scale cloud migration, especially at terabyte or petabyte scale, it's not enough to just 'use' AWS Snowball. There's a strategy behind it wherein every decision on preparing the data, structuring jobs, and validating transfers impacts speed, cost, and security.
AWS Snowball isn't a plug-and-play device but a cloud migration tool that demands preparation, structure, and smart execution.
Below, we’ve laid out the best practices which help you actually get value out of the Snowball investment.
#1. Assess transfer size & frequency
Before anything else, get clear on how much you’re moving and how often. Whether you’re shifting terabytes once or petabytes quarterly, the volume shapes everything—timeline, device type, even shipping.
Estimate WAN vs. Snowball transfer feasibility
-
Use network calculators to assess the estimated time and cost of transferring data over your WAN or consult with a trusted cloud migration service provider to get better insights.
-
Compare this against the turnaround time of a typical AWS Snowball data migration, which is often significantly faster and cheaper at petabyte scale.
Group and prioritize data sets
- Identify which data sets can be moved in bulk and which need to be isolated for compliance or project-specific reasons.
- Segment data by criticality or frequency of access to determine the ideal sequencing.
Use AWS Migration Evaluator
- The AWS Migration Evaluator is a free tool that provides a report based on your current infrastructure usage, forecasting cost and time for cloud migration.
- It us useful in when pitching budgets internally or justifying Snowball over direct-connect transfers.
#2. Optimize file system for transfer
An unorganized or incompatible file system can drag your migration down. Cleaning things up and making your data structure Snowball-ready is key.
Flatten nested folders
- Excessively nested directories can lead to path-length errors and slow file indexing.
- Reorganize your files into a shallower structure to ensure faster directory scans and smoother uploads.
Avoid symbolic links
- Symbolic or soft links often confuse the transfer process, sometimes resulting in missing or duplicated files.
- Replace links with physical copies of the referenced files, or restructure the hierarchy altogether.
Use parallel jobs for large datasets
- If the volume surpasses AWS Snowball capacity, request multiple Snowball devices.
- Assign separate jobs to each and run transfers in parallel to reduce total time spent on the operation.
#3. Pre-validate your data
Before you ship, make sure the data you’re sending is complete, accurate, and verifiable. Pre-validation eliminates unpleasant surprises later.
Use checksum comparison tools
- Tools like md5sum, shasum, or built-in file hashing scripts can help create fingerprint checks of your source files.
- These hashes should be retained and compared after the migration to confirm file integrity.
Maintain logs for before-after verification
- Create a CSV or log file that captures file names, sizes, hash values, and modification timestamps.
- After upload, match the log entries against S3 file properties or AWS checks to verify successful transmission.
#4. Encrypt at source and validate at destination
Encryption isn’t just a checkbox but a key part of secure Snowball data transfer. Encrypt your data locally, and don’t assume it will work as expected on arrival.
Use AWS KMS integration to manage encryption keys
- When configuring the Snowball job, choose to use KMS-managed keys or import your own.
- KMS automates key lifecycle management and makes decryption easier once the device is returned.
Confirm successful decryption before decommissioning source
- Run trial decryptions post-upload, especially if using customer-managed keys.
- Only after confirming file integrity on AWS should the original on-prem copy be archived or deleted.
#5. Automate with Snowball API & CLI
With AWS Snowball CLI and API, you can bake repeatability, accuracy, and efficiency directly into your data migration pipeline.
It frees your team from repetitive tasks and ensures consistency across transfers.
Set up job creation, file staging, and status checks via AWS CLI
- Use AWS CLI commands to create Snowball jobs programmatically, assign device shipping addresses, and define data targets (like specific S3 buckets and prefixes).
- Automate file staging by writing scripts that prepare and copy data using multipart transfers or batched operations.
- Set up automated checks that poll job status, report completion, or flag failures to make sure you always know where your job stands without manually logging into the console.
Integrate with custom CI/CD for automation
- Plug Snowball commands into Jenkins, GitLab CI, or any automation framework to trigger data export/import routines as part of a deployment or update cycle.
- Teams pushing large build artifacts, compliance snapshots, or backups to the cloud as part of DevOps flows can benefit from CI/CD automation services.
- You can also set logic to initiate a Snowball job when data size thresholds are met or when edge systems hit defined usage patterns.
#6. Use Edge computing where applicable
Using edge compute is a smart move when your migration involves remote environments or data that needs cleaning up before being sent to the cloud.
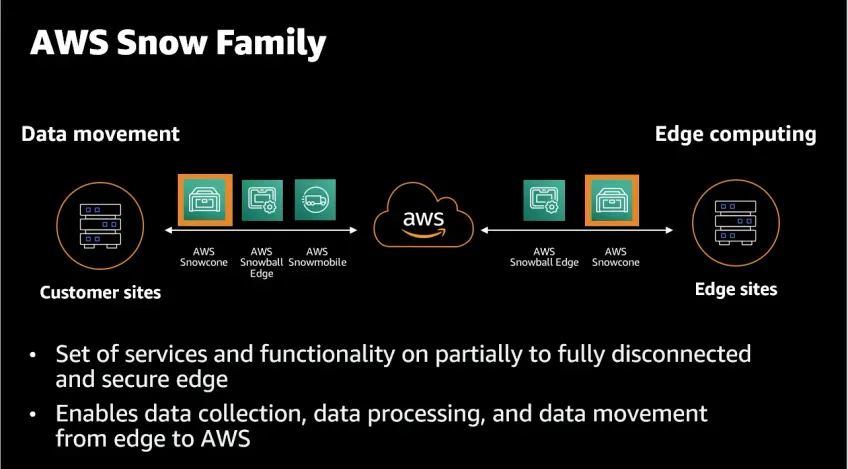
With AWS Snowball Edge, you can run compute functions directly on the device itself, saving transfer time and improving efficiency.
Preprocess data at edge using Lambda functions inside Snowball
- Deploy AWS Lambda functions inside Snowball to handle tasks like image resizing, metadata tagging, or initial filtering.
- This helps in reducing the volume of data before uploading to AWS, which saves time and bandwidth. Use the Snowball Edge console or CLI to configure Lambda jobs ahead of shipment.
Common in IoT, video surveillance, field data processing
- If you're running IoT networks or deploying video surveillance in places with poor connectivity, Snowball lets you store, process, and analyze data on-site.
- You can cache the data temporarily, perform event-driven analysis, and send only refined results to S3.
- This reduces the load on your network while supporting real-time or near-real-time decisions in remote locations.
#7. Plan Chain-of-Custody and Logistics
The chain-of-custody protocol defines how data remains secure while in motion while covering every touchpoint, from packaging to AWS ingestion.
Define SOPs for physical handoff and device tracking
- Create documented procedures for who handles the device, how it’s transported, and where it’s stored temporarily.
- Assign personnel responsibilities at each step and log device movement to minimize security risks.
Ensure regional compliance (e.g., customs handling for international shipping)
- Cross-border shipping may require customs declarations, permits, and sometimes special clearance.
- Understand local data regulations in destination and origin countries to avoid fines or seizure.
- AWS provides shipping and compliance guides—use them to prep in advance.
#8. Run test transfers first
You get to validate every single component in your Snowball workflow, from file system compatibility to decryption at the destination.
Simulate a test run of ~1 TB to benchmark time, success rate
- Select a 1–2 TB sample of actual production data, with similar file types, formats, and structure.
- Monitor time taken for each phase—data load, job configuration, shipping turnaround, S3 ingestion.
- Measure against business SLAs or expectations to decide whether Snowball is fit-for-purpose.
Adjust packaging and validation scripts accordingly
- If errors occur during staging or ingestion, revise folder structures, tweak file naming, and optimize validation scripts (checksum logs, ACLs, encryption test routines).
- Document improvements in a checklist so the full migration run replicates the most stable test path.
- Use this opportunity to train teams on SOPs and simulate incident resolution under timed conditions.
#9. Validate Against AWS Well-Architected Framework
Treat every Snowball project as an extension of your overall cloud architecture.
Aligning your process with AWS Well-Architected Framework (WAF) ensures you’re not just moving data—but doing it right.
Tie Snowball use to reliability and operational excellence pillars
- Within reliability: ensure backup redundancy, error-handling scripts, and recovery workflows are in place.
- Within operational excellence: log job scripts, version control, and automate device lifecycle actions to minimize human dependency.
- Use AWS well-architected framework lenses to assess gaps before executing large-scale transfers.
Document all transfer architecture for audits
- Keep an organized repository of everything: job IDs, key management details, transfer timings, hash validations, CLI outputs.
- This documentation not only helps with internal review but is often required in regulated industries.
- Tie this into broader compliance programs (SOC 2, ISO, HIPAA) by cross-referencing Snowball’s encryption and validation features.
#10. Post-Migration Optimization
Once your files are in S3, your migration is technically done—but operationally, it’s just beginning. How you manage, store, and use that data determines whether the move was worth it.
Use S3 lifecycle policies to tier archived data
- Tag data during migration—hot, warm, cold—so lifecycle transitions can be automated.
- Configure rules to move inactive data to Glacier after X days or delete redundant archives after a defined retention period.
- These rules save you storage costs, especially when you're working with petabyte-scale logs or backup dumps.
Enable AWS Glue or Athena for data query and transformation
- Set up a Glue Crawler to automatically catalog files into tables. Create ETL jobs to transform unstructured or semi-structured data.
- Athena allows SQL queries directly over S3 without needing to spin up new compute instances.
- Combine this with tools like QuickSight or Redshift Spectrum if your data feeds into dashboards or analytics workflows.
Top 5 Mistakes businesses make with AWS Snowball & their fixes

Snowball data migration, a small oversight can mean hours of delay or thousands in costs. Here's a breakdown of the most common pitfalls and exactly how to sidestep them.
Mistake #1: Not accounting for import/export fees and shipping delays
Delays also impact project timelines—especially if the device is stuck at customs or held up during transit.
And if you’ve planned your entire data center shutdown around that transfer then that delay turns into a critical issue.
How to avoid it:
- Budget for hidden costs: Factor in AWS Snowball pricing, insurance, and international taxes when planning the job.
- Buffer your timelines: Add 2–5 business days per shipping leg to accommodate clearance and unexpected hold-ups.
- Use AWS Pricing Calculator: Pre-calculate your costs using AWS calculator.
Mistake #2: Failing to align region compatibility
Each Snowball device is region-specific. If you order a Snowball from the wrong AWS region or attempt to import into an S3 bucket hosted elsewhere, the job may fail or get rejected entirely.
How to avoid it:
- Check region availability: Confirm your region supports Snowball here by navigating its FAQs.
- Plan region-specific workflows: Don’t ship across regions. Use a Snowball sourced in the same region as your destination S3 bucket to keep transfers seamless.
Mistake #3: Skipping test validation before committing production data
Skipping dry runs can cost you—files might get corrupted, directory structures might fail, and permissions may be missing. Worse? You won't know until it’s too late.
How to avoid it:
- Run a pilot migration: Transfer 1–2 TB using a mirror of your intended folder structure.
- Validate checksums pre- and post-transfer: Use tools like md5sum or shasum to confirm file integrity.
- Refine workflows: Update automation scripts, naming conventions, and permission logic based on your test outcome.
Mistake #4: Overlooking S3 bucket permissions after import
You’d ideally ship terabytes of data using AWS Snowball, complete ingestion to S3. But, what if users can’t access the data?
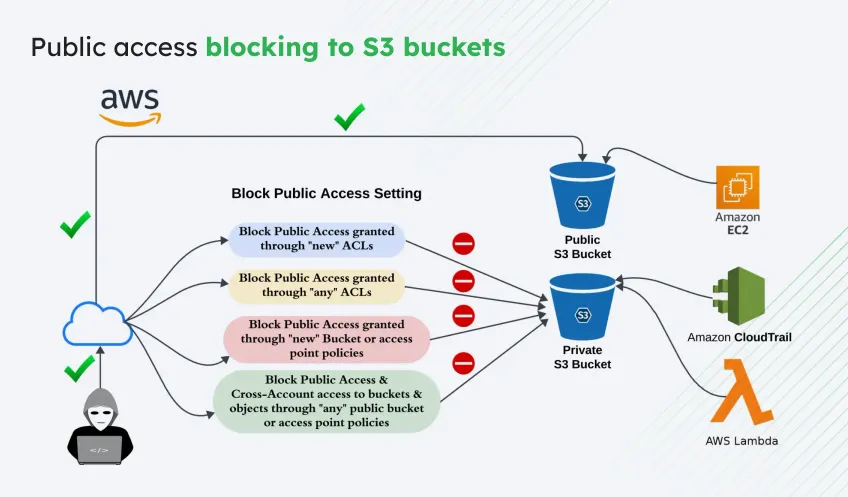
Its a mistake that typically stems from overlooked IAM policies, mismatched bucket permissions, or a lack of predefined access roles. Without proper access configurations, services like Athena, Glue, or even internal users won’t be able to use the newly migrated data.
How to avoid it:
- Predefine roles and permissions: Use IAM policies to manage who sees what.
- Map job to bucket correctly: Confirm the job points to the right S3 prefix and that the bucket allows access.
- Test read/write: Run a basic access test post-import to validate.
Read more: 10 Questions to Ask Before Hiring an AWS Cloud Consultant
Mistake #5: Treating Snowball as a one-time use instead of a repeatable process
if you’ve got remote offices, regular backups, or edge deployments, Snowball can—and should—be part of your ongoing data strategy.
Treating Snowball as disposable misses its real value: repeatability, automation, and edge processing. Snowball isn't just a device but a secure data transfer solution that fits well into hybrid and distributed workflows.
How to avoid it:
- Document your process: Capture steps from device ordering to final decryption.
- Automate regular jobs: Use the AWS Snowball CLI or API for recurring transfers.
- Use edge compute: Tap into Snowball’s compute power to format, filter, or compress data before sending it.
Conclusion
Data migrations requires setting up your business for speed, reliability, and growth in the cloud. And with the scale many organizations operate at today, AWS Snowball becomes a powerful tool offering a solid foundation for a modern cloud strategy.
Again, it isn’t just about using the device but understanding the entire process, optimizing each stage with best practices, and avoiding the costly missteps others have learned the hard way.
So, if you’re running a one-off lift or managing ongoing hybrid workloads, the approach you take with AWS Snowball determines how successful your cloud journey will be.
Do you nedd expert assistance in planning, automation, or end-to-end managed services? Consult AWS experts at Peerbits to unlock the full potential of Snowball.










