

Electronic Case Report Form systems are the data backbone of clinical research. Every adverse event, efficacy endpoint, and protocol deviation your trial generates lives in your eCRF — and the data quality, regulatory defensibility, and system uptime of that eCRF directly determines whether your submission will survive FDA or EMA scrutiny. Yet the majority of eCRF systems built for small trials — 3 sites, 150 subjects — make architectural commitments in the first sprint that become catastrophic liabilities at 80 sites and 12,000 subjects. This is not a tooling problem. It is a design problem.
of FDA 483 observations in clinical data management cite eCRF audit trail deficiencies
average cost overrun when eCRF systems require schema redesign mid-trial
of scale failures trace back to one of the first three architectural mistakes below
1. Monolithic Study Database Schema That Can't Evolve Mid-Trial
The single most destructive eCRF architecture mistake is building a monolithic study database schema — one that encodes the protocol's CRF structure directly into relational table definitions. When you create a table called VISIT_2_VITALS or ECG_TIMEPOINT_WEEK_12, you've made a schema amendment a database migration. And protocol amendments — which happen in virtually every Phase II/III trial — require a database migration.
In a regulated environment under 21 CFR Part 11, database schema changes must be validated, change-controlled, and documented in your Computer System Validation (CSV) package. Every structural change to a study database triggers a partial or full revalidation. Teams running monolithic schemas spend 40–60% of their data management budget on schema amendment cycles rather than data collection and cleaning.
Tables: SCREEN_LABS, WEEK4_LABS, WEEK8_LABS. Each protocol increment requiring a new monolith odds a new table, a migration script, a validation protocol, and a CRF schema update. 12 migrations = 12 validations.
Core tables: SUBJECT, VISIT, FORM, ITEM, ITEM_DATA. CRF structure lives in metadata, not DDL. Protocol amendments update the metadata layer — zero database migrations, zero schema revalidation cycles.
The metadata-driven approach (used by purpose-built EDC platforms like Medidata Rave, Oracle Clinical One, and OpenClinica) separates the data model (static, stable, validated once) from the study definition (CRF structure, edit checks, visit schedules — changeable without schema impact). Building a custom eCRF without this separation is building technical debt that compounds with every protocol amendment.
🚨 Regulatory consequence: A monolithic eCRF schema amendment without a supporting validation protocol and system change control record is a 21 CFR Part 11 finding. FDA inspectors specifically review system change logs against validation documentation. Undocumented schema changes = untested system = potentially unreliable data.
Peerbits Services - EHR Integration Services
2 Audit Trail Architecture That Doesn't Survive 21 CFR Part 11 Scrutiny
21 CFR Part 11 — the FDA's regulation for electronic records and electronic signatures — mandates that any system used to create, modify, or maintain records used in regulated submissions must maintain a complete, computer-generated, time-stamped audit trail that captures the date and time of operator entries and actions that create, modify, or delete electronic records. This is non-negotiable. An eCRF without a compliant audit trail cannot support a regulatory submission.
The failure pattern isn't usually no audit trail — it's an audit trail that fails in one of three ways at scale:
-
Audit trail stored in the same transactional database as live data. At scale, the audit log table grows faster than the clinical data table. Queries that join live data to audit history for data review become table scans against millions of rows. Some teams respond by truncating or archiving old audit entries — which is a regulatory violation.
-
Audit trail captures "what changed" but not "from what to what." 21 CFR Part 11 requires capturing the original value, the new value, the reason for change (if required by the protocol), and the identity of who made the change. Systems that log only ITEM_DATA UPDATED without the before/after values fail inspection.
-
Audit trail is mutable. Users with database-level access can delete or modify audit records. A compliant audit trail must be write-once — technically unmodifiable, not merely access-controlled.
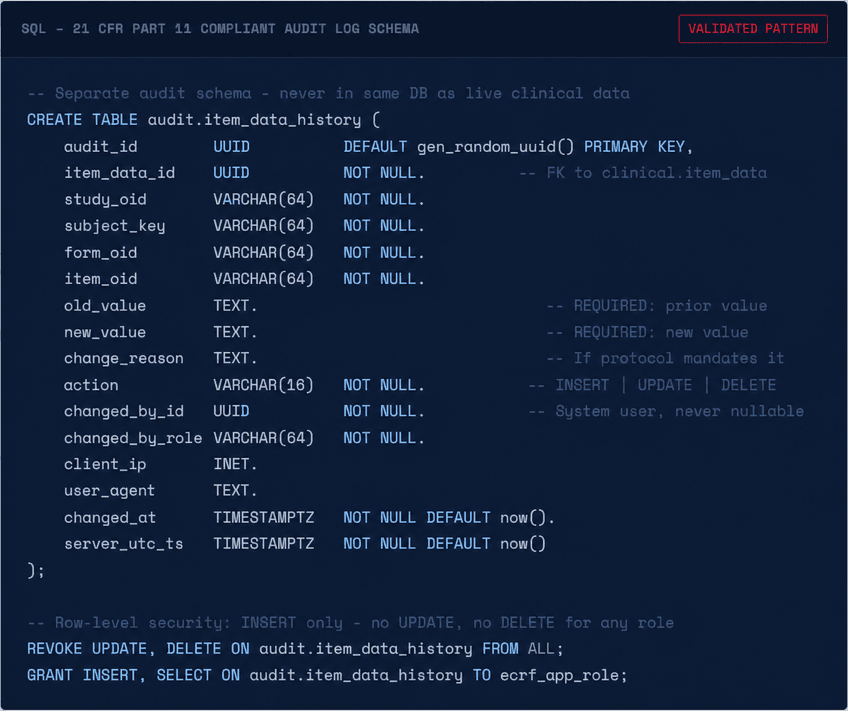
Use of computer-generated, time-stamped audit trails to independently record the date and time of operator entries and actions that create, modify, or delete electronic records. Record changes shall not obscure previously recorded information and audit trail documentation shall be retained for a period of at least as long as that required for the subject electronic records.
3. Form Versioning That Doesn't Track Subjects Across Protocol Amendments
Protocol amendments produce CRF amendments. A subject enrolled before Amendment 3 may have Week 4 data captured on CRF v1.2. After Amendment 3, Week 4 adds a new safety assessment — captured on CRF v1.5. At database lock, your eCRF must clearly identify which version of each CRF was used to collect each data point, for every subject. An eCRF that overwrites the active CRF definition and re-renders historical data against the new form version destroys traceability.
The correct architecture maintains an immutable CRF version registry where each form version is a new, independently addressable object. Subject data records carry a crf_version_id foreign key — not just a form_oid. This allows the system to render historical data exactly as it was collected, while showing current subjects the active form version.
Peerbits Services - Medical Coding at AI Speed
4. Query Management Architecture That Collapses Under Multi-Site Load
Clinical data queries — discrepancy notices raised by data managers when site-entered data fails validation or appears inconsistent — are the operational heartbeat of a running trial. A Phase III trial with 80 sites and 4,000 subjects may have 20,000 open queries at any given time. eCRF systems that store query state in their primary transactional database with no dedicated query workflow engine become progressively slower as the query backlog grows — because query dashboards require joining clinical data, form metadata, user assignments, site configurations, and query history in a single page load.
The fix is architectural separation: queries are a workflow object, not a database record. They belong in a dedicated query management service with its own read-optimized store, indexed by site, form, item, assignee, and status independently. Query state transitions (Open → Answered → Closed / Reopened) should be event-sourced — every state change is an immutable event, not an in-place update. This gives you a complete query lifecycle history without additional audit logic, and decouples query load from CRF data entry performance.
⚠️ Performance benchmark: A well-architected query management service should handle 50,000 concurrent open queries across 100 sites with sub-200ms dashboard load times. If your eCRF query dashboard takes more than 2 seconds to load at 10,000 open queries, your query architecture will not survive a large Phase III trial.
5. No Offline Data Capture — Assuming Persistent Connectivity at All Sites
Clinical trial sites include academic medical centers with robust IT infrastructure — and community clinics in rural Kenya, hospital networks in Southeast Asia, and research units in facilities where internet connectivity is intermittent. An eCRF system with no offline capability excludes these sites from electronic data capture entirely, forcing them back to paper — which then requires manual transcription, which is exactly the data quality problem eCRF was meant to solve.
Offline mode is architecturally non-trivial in a regulated environment because every offline data entry must be reconcilable with the server state without conflicts, and the audit trail must capture both the original entry timestamp (device clock, validated) and the server receipt timestamp. Common failure modes in offline eCRF implementations include:
-
Conflict resolution that silently overwrites. When an offline session syncs and finds a conflict (the same field edited both offline and by a data manager online), a silent last-write-wins resolution is a data integrity violation. Conflicts must surface as queries for human resolution.
-
Device clock manipulation. Offline entries timestamped by device clock are vulnerable to intentional or accidental clock manipulation. The system must flag entries where the device timestamp differs materially from the server receipt timestamp, and require investigator attestation for the discrepancy.
-
Partial form sync without transactional integrity. A form submission must sync atomically — all items committed or none. Partial syncs that commit some items and leave others pending produce incomplete records that fail edit checks unpredictably.
6. Validation Rule Sprawl — Edit Checks That Nobody Can Maintain
Edit checks (automated data validation rules that fire during or after entry) are the primary mechanism for catching data quality issues at the point of entry. A well-designed edit check library catches protocol deviations, out-of-range values, and missing mandatory data before they become queries. A poorly managed edit check library becomes a maintenance nightmare that fires incorrect queries at scale, training site staff to ignore or auto-answer warnings — destroying the value of the entire quality system.
The scale failure pattern is edit check proliferation without governance: each data manager adds edit checks to catch problems they've seen, without a canonical library, without coverage analysis, and without firing rate monitoring. At 200+ edit checks, a meaningful percentage will fire incorrectly due to population distribution changes, protocol amendments that invalidate their logic, or site-specific exceptions that were never parameterized.
💡Architecture fix: Implement edit checks as a parameterized rule engine — each check is an instance of a typed rule template (RangeCheck, CrossFormCheck, TemporalCheck, ConditionalRequiredCheck) with parameters stored in the study metadata layer. This enables firing rate monitoring per rule, automated regression testing on amendment, and site-level exception configuration without forking rule logic.
7. Broken CTMS and Central Lab Integration — Data Silos Mid-Trial
A functioning clinical trial generates data from at least four systems simultaneously: the eCRF (site-entered clinical data), the CTMS (Clinical Trial Management System — site contacts, monitoring visits, IRB submissions), the central lab (hematology, chemistry, PK samples), and the IxRS/RTSM (randomization and trial supply management). In most trial technology stacks, these systems are integrated at launch — and the integrations silently degrade over the course of the trial as system versions change.
The most consequential integration failure is between the eCRF and the central lab system. Lab results are typically transmitted as HL7 v2 ORU messages or flat-file exports into the eCRF. When this integration breaks — which it does, routinely, due to lab LIMS upgrades, format changes, or network issues — lab data either stops populating, populates to wrong subjects, or populates without triggering the edit checks that compare lab values against CRF-entered vitals. The result is a dataset where eCRF data and lab data are misaligned, discoverable only during database lock cleaning — the most expensive point to fix it.
Peerbits Services - AI Medical Scribe
8. Randomization and Blinding Gaps in the eCRF Data Layer
In blinded trials, the eCRF must enforce treatment blinding at the data layer — not just at the UI layer. A common eCRF design mistake is implementing blinding as a display filter: the treatment assignment field exists in the database, visible to anyone with database query access, and the application simply doesn't render it for blinded roles. This is a thin blind, not a true blind.
Proper blinding architecture stores treatment assignment data in a physically separate, access-controlled schema that is not accessible to the eCRF application database user. The unblinding key lives in the IxRS/RTSM system, which is the system of record for randomization. Emergency unblinding must follow a documented, audited workflow — not a database query. Any unblinding event must generate an audit record that includes who requested it, the clinical justification, and whether it was a single-subject or full-trial unblinding.
9. Multi-Site Role Architecture That Doesn't Scale to 100+ Sites
eCRF role architecture that works at 5 sites breaks at 100. The failure mode is role assignment explosion: in a naive implementation, every user gets a role per study, and every role assignment is a database record. With 80 sites averaging 6 users each, across 3 active studies, you have 1,440 role assignments to maintain — before accounting for staff turnover, which in clinical research runs at 20–30% annually.
The scalable architecture uses site-scoped role templates assigned at the site level, not the user level. A site's Principal Investigator role template defines what all PIs at that site can see and do in the eCRF. Adding a new PI to site 047 is one assignment, not a matrix of per-form, per-visit, per-role permissions. Role inheritance from the site level to the user level is computed at query time, not stored per-user.
Additionally, multi-site eCRFs need a data visibility model that prevents sites from seeing each other's subject data while giving sponsors, CROs, and data managers cross-site views. This must be enforced at the query layer — not as a UI filter over a global dataset.
10. Database Lock and Study Closeout Architecture That's an Afterthought
Database lock — the formal process of freezing a trial dataset for statistical analysis — is where eCRF scale failures become visible in the most painful way. A trial that has accumulated technical debt across the preceding nine failure modes arrives at database lock with: misaligned audit trails, inconsistent CRF versions across subjects, a query backlog that can't be cleared at scale, and an export pipeline that can't produce CDISC-compliant SDTM or ADaM datasets without manual transformation.
Database lock should be an orchestrated, automated workflow — not a manual checklist. Key requirements for a lock-ready eCRF architecture:
-
Lock preconditions are machine-checkable. Zero outstanding mandatory queries, all required fields complete, all subject statuses resolved — these checks run automatically and produce a lock readiness report. No human should be manually reviewing 4,000 subject records to verify lock readiness.
-
CDISC SDTM export is built-in, not a post-processing script. Your eCRF data model should map to SDTM domains at design time, not at closeout. Every item in the CRF should have a SDTM variable mapping maintained in the study metadata. Export then becomes a query against the metadata-driven model, not a custom ETL.
-
Post-lock data correction workflow is regulated. After lock, corrections require a formal unblind or amendment procedure with documented justification, re-lock, and audit trail continuity. An eCRF that allows post-lock edits via a superuser bypass produces a dataset whose integrity is legally indefensible.
-
Archive package meets 21 CFR Part 11 retention requirements. The archived dataset, audit trails, validation documentation, and system configuration must be preserved in a format that can be reviewed by FDA up to 2 years after the study's marketing approval — which may be a decade or more from study close.
🚨Submission risk: An eCRF dataset submitted to FDA or EMA as part of a marketing application is subject to full audit during the review cycle. Inspectors will request the original audit trail, the validation documentation, and system access logs. An eCRF system that cannot produce all three — in their original, unmodified form — places the entire submission at risk of a Complete Response Letter or clinical hold.
Get a Free eCRF Architecture Audit
Peerbits engineers have built and audited eCRF and EDC systems across Phase I–IV trials, spanning FDA, EMA, and PMDA submission environments. Our engagements cover metadata-driven architecture design, 21 CFR Part 11 compliance gap analysis, audit trail remediation, CDISC mapping, and scale readiness assessments for trials moving from proof-of-concept to global Phase III.
Our eCRF Architecture Review is a 5-day engagement delivering a written findings report with a regulatory compliance scorecard, a scale readiness assessment, and a prioritized remediation roadmap.
Book Your Free eCRF Audit








