

Generic computer vision models often struggle to deliver the accuracy and reliability to your project needs. You might have lots of data but face difficulties turning it into a model that truly understands your images. Training with the wrong tools or skipping key steps can lead to wasted time and missed opportunities.
That’s where building and training custom computer vision models with PyTorch makes a difference. PyTorch provides a modern and flexible framework designed to handle your unique challenges, whether you are working on image classification, object detection, or other complex tasks.
This guide walks you through the essential steps from preparing your data and selecting the right computer vision libraries to designing and training models that perform well. You’ll discover how to overcome common computer vision challenges and develop PyTorch computer vision models custom to your needs.
When and why custom models make sense for you?
If your project requires more than generic tools, custom computer vision services help build models that fit your unique data and goals. Knowing when to switch from pre-trained models can save time and improve results.
1. How to tell pre-trained models no longer meet your needs
Pre-trained models provide a robust foundation but often lack the precision needed for specialized tasks. When accuracy drops or the model struggles with your unique data, it’s a sign that customization is necessary. Understanding these limitations helps you decide when to move beyond generic solutions.
- Your model’s accuracy isn’t high enough for your application
- Your data includes features or details not captured by generic models
- Domain-specific images cause frequent errors or missed detections
2. Industries where custom computer vision models add real value
Some industries have unique requirements that off-the-shelf models can’t satisfy. Custom computer vision models excel in fields where precision and domain-specific knowledge matter, enabling automation and better decision-making. These models are especially useful where visual data varies significantly from common datasets.
- Manufacturing for detecting defects and improving quality control
- Healthcare for analyzing unique medical images or scans
- Logistics for automating package sorting and tracking
- Retail for personalized product recognition and inventory management
3. What return you can expect from a well-trained custom model
Investing in custom computer vision models often leads to significant benefits. These models improve accuracy, reduce manual workload, and speed up processes, ultimately driving cost savings and better customer experiences. Knowing the expected return can help justify the effort and investment involved.
- Increased accuracy tailored to your specific use case
- Reduced manual work and faster processing times
- Cost savings through automation and error reduction
- Improved customer satisfaction and competitive edge
What you will need before you build
Before you get AI development services for your custom computer vision models, you need the right foundation. This includes quality data, clear project goals, strong infrastructure, and the right people to bring it all together. Skipping any of these can slow progress or lead to underperforming models.
Clean, labelled image data
Your model is only as good as the data it learns from. Without clean, well-annotated image datasets, even the best algorithms won’t perform well. You need data that reflects the real-world scenarios your model will face.
- Collect enough images to represent all possible use cases
- Make sure the images are correctly labelled and consistently annotated
- Include edge cases and real-world noise in your dataset
Define your goal clearly
Knowing what you want your model to do helps you choose the right model architecture and training strategy. Each task requires different data and training techniques.
- Image classification: Identify the category of an object
- Object detection: Locate and classify objects in an image
- Image segmentation: Label pixels to distinguish object boundaries
Infrastructure setup
Training deep learning models, especially in PyTorch for computer vision tasks, can be resource-intensive. Whether you’re using local machines or cloud platforms, your setup should support large-scale data processing and training.
- Use GPUs or TPUs for faster training
- Plan for large storage to handle image datasets and model checkpoints
- Decide between on-premise or cloud based on your team’s expertise and scalability needs
Building the right team: in-house vs hiring experts
Your results depend heavily on the team handling model development. If your internal team lacks deep learning experience, consider bringing in right computer vision consulting partner.
| Criteria | In-house team | Hiring experts (outsourced) |
|---|---|---|
| Control | Full control over priorities and direction | Shared control based on scope and contracts |
| Domain knowledge | Deep understanding of your business context | May need time to align with your domain |
| Speed of execution | May be slower if team lacks experience | Faster setup and delivery due to expertise |
| Upfront investment | Higher (hiring, training, infrastructure) | More flexible; pay for specific outcomes |
| Scalability | Requires planning and hiring over time | Easily scale team size and capabilities |
| Expertise in tools | Varies; may need training in PyTorch, CV | Immediate access to PyTorch and CV specialists |
| Long-term cost | Lower if team stays long-term | Higher over time if scope keeps expanding |
| Best for | Long-term vision, in-house innovation | Faster go-to-market, short- to mid-term goals |
Step-by-step: Building your custom computer vision model
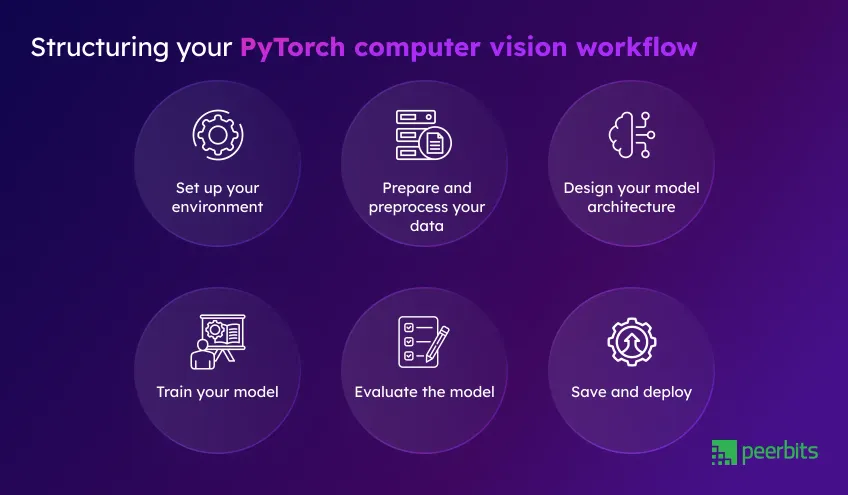
Even if you're not getting hands-on with the code, understanding the steps behind building a custom computer vision model helps you manage timelines, resources, and outcomes better. Below is a clear breakdown of each stage, blending the technical flow with the strategic perspective.
1. Set up your environment
Before AI software development starts, you need a proper environment to support deep learning for computer vision. This includes both software and hardware to handle model building and training.
- Use Python-friendly IDEs like VS Code or Jupyter
- Install libraries such as PyTorch, Torchvision, and Albumentations
- Ensure access to GPUs (NVIDIA CUDA) or cloud platforms with compute support
2. Prepare and preprocess your data
Raw image data isn't ready for training right away. Preprocessing helps the model learn faster and more accurately. This step shapes the dataset into something your model can understand and generalize from.
- Resize images to a consistent shape
- Normalize pixel values to maintain scale
- Apply augmentation techniques (flipping, rotation, brightness) for robustness
- Use tools like Albumentations or Torchvision’s transforms module
3. Design your model architecture
This is where the core of your custom model begins. You can either build a new architecture or fine-tune an existing one like ResNet. The choice depends on the complexity of your task and the volume of your training data.
- Choose between starting from scratch or transfer learning
- Use proven structures like CNNs or pre-trained ResNet variants
- Add custom layers for task-specific outputs if needed
4. Train your model
Training is where the model learns from the data. The key here is to use the right training settings while keeping an eye on overfitting or underperformance.
- Set up loss functions (e.g., CrossEntropy, MSE)
- Choose optimizers like Adam or SGD
- Define batch size and number of training epochs
- Track both training and validation accuracy to gauge learning progress
5. Evaluate the model
Once trained, the model’s performance must be measured using relevant metrics based on your objective (classification, detection, segmentation).
- For classification: accuracy, precision, recall, F1 score
- For detection: Intersection over Union (IoU), confusion matrix
- Evaluate on real-world test data for a practical score
6. Save and deploy
After evaluation, the model is saved in a deployable format. You can then export it to run in various environments, whether in the cloud or on edge devices.
- Save trained models as
.pthor.ptfiles - Export using TorchScript or convert to ONNX for broader compatibility
- Deploy to cloud APIs, mobile apps, or embedded devices depending on your use case
Tuning your model for better performance
Once your model is trained, the next step is improving its performance without rebuilding everything from scratch. This is where tuning makes a real difference. Whether you're using PyTorch for computer vision or combining custom strategies, the right fine-tuning can save both time and compute resources.
Apply transfer learning and fine-tune smartly
Leverage pre-trained models instead of training from scratch. This approach helps reduce training time while giving you a strong base, especially when data is limited.
- Use architectures like ResNet, EfficientNet, or MobileNet trained on ImageNet
- Replace the final layers with custom outputs for your specific task
- Unfreeze selected layers for fine-tuning on your dataset
- This is widely used in both PyTorch computer vision models and practical business use cases
Use smart hyperparameter optimization
The learning rate, batch size, and optimizer you choose can impact your model more than you'd expect. Instead of adjusting values manually, automated tuning tools can give faster and more reliable results.
- Manual tuning involves trial and error
- Automated tuning with tools like Optuna improves accuracy efficiently
- Parameters to focus on: learning rate, dropout, number of layers, optimizer choice
- This is a common step in deep learning for computer vision workflows
Handle overfitting and underfitting
A model that’s too “perfect” on training data might fail in the real world. On the flip side, a model that never learns enough also won’t be useful. Tuning helps balance both extremes.
- Use dropout and regularization to avoid overfitting
- Add data augmentation to make your model more robust
- Adjust model complexity (e.g., reduce layers) if underfitting persists
- Evaluate performance across both training and validation sets
Making your model production-ready
A custom computer vision model built with PyTorch holds real value only when it's deployed effectively. Production readiness means your model can deliver real-time insights, stay responsive under varying loads, and adapt as your data evolves. Below are the key points you should consider before you hire AI developers.
Real-time inference setup
When speed matters, like in logistics tracking, quality control, or surveillance, your model must respond fast and without delays. Setting up real-time inference is the first step to making your predictions usable in everyday workflows.
- Use batch or single-frame prediction depending on the use case
- Optimize your model with tools like TorchScript or ONNX
- Deploy on environments that fit your business like cloud servers, edge devices, or hybrid setups
- Balance latency with accuracy depending on task criticality
Model serving options: Flask, FastAPI, or TorchServe
To connect your model with applications, you need a serving layer. Each option offers different strengths based on scale, speed, and flexibility.
- Flask: Great for early-stage demos or testing small PyTorch vision models
- FastAPI: More performant for asynchronous or multi-user requests
- TorchServe: Designed for PyTorch for computer vision workloads; offers version control, metrics, and scalable deployment out of the box
- Consider ONNX for cross-platform support and GPU inference on non-PyTorch stacks
Monitoring model behavior in production
Even great models can slip if the data shifts. Keeping your model relevant means staying ahead of performance issues with regular monitoring and maintenance.
- Track latency benchmarks and prediction throughput
- Watch for signs of data drift in visual data
- Log accuracy over time to decide when retraining is needed
- Build triggers for retraining based on input patterns
What challenges you should expect

Building and deploying computer vision models is not always smooth. If you're using PyTorch for computer vision tasks, certain hurdles often show up when working with business data or scaling to production. Here’s what to watch out for and how to stay ahead.
Bad data leads to bad predictions
One of the biggest computer vision challenges is working with messy or skewed data. If the data is not clean or balanced, it can affect everything from training accuracy to final predictions.
- Mislabelled or inconsistent annotations can throw off your model
- Imbalanced classes (e.g., more of one category than another) lead to biased results
- Manual cleaning is slow, and automation tools need setup
- Consider data augmentation or synthetic data to balance your dataset
Training feels stuck
Your model might train well at first, then stop improving. Well, this is common, especially with image classification using PyTorch or object detection pipelines.
- Learning rate might be too high or too low
- You could be overfitting to training data without noticing
- Model architecture may not match your data complexity
- Try checkpointing, loss function changes, or transfer learning from stronger baselines
Scaling inference to production use
It is one thing to get good validation scores. It’s another to serve results fast when hundreds or thousands of users are relying on it. Scaling your inference layer is a serious step.
- Poorly optimized models may slow down under real-time loads
- Choosing between edge and cloud deployments can get tricky
- You’ll need GPU support or consider gpu cloud hosting for large-scale video/image inputs.
- Use tools like TorchServe or FastAPI with load balancing to manage traffic
The tricky path from prototype to production
Going from notebooks to live APIs takes more than a good model. Production readiness means clean code, tracked metrics, and proper environment setups.
- Lack of documentation or version control causes deployment delays
- Integration with existing software systems can require custom APIs
- Testing for edge cases and security is often skipped under tight deadlines
- Using proven deployment frameworks with observability tools saves time later
Conclusion
Building and training custom computer vision models with PyTorch is not just for tech labs anymore. It’s a practical way to solve real business problems using your own data, goals, and context.
From spotting the limits of pre-trained models to setting up your infrastructure, designing your model, training and fine-tuning, and finally putting it into production, each step brings you closer to smarter and faster decision-making. When done right, this process can improve accuracy, cut down on manual work, and unlock insights that generic tools simply can’t.
Whether you're dealing with image classification using PyTorch or complex object detection in logistics or healthcare, the shift toward custom computer vision models gives you more control and flexibility. With the right foundation and the right focus, PyTorch for computer vision can help you turn your data into real results.

FAQs
It depends on the complexity of your use case, data availability, and team experience. A simple prototype may take a few weeks, while production-grade models often take a few months.
Yes. PyTorch supports transfer learning, letting you fine-tune pre-trained models like ResNet or EfficientNet on your own dataset.
While PyTorch is mostly code-based, platforms like PyTorch Lightning and Roboflow can simplify training and data handling.
Costs can vary based on GPU usage, data labeling, storage, and engineering time. Cloud platforms usually charge hourly for GPU compute.
If certain classes or image types consistently underperform, your dataset may be unbalanced. Bias audits and class-wise accuracy checks help reveal this.
Yes, especially with techniques like data augmentation, transfer learning, and regularization. PyTorch gives you flexibility to adjust these.
Yes. Use PyTorch Mobile or convert models to ONNX and run them using cross-platform runtime environments.
Manufacturing, healthcare, logistics, agriculture, and retail see strong ROI when off-the-shelf models fall short.
It depends on how fast your data changes. You may need to retrain quarterly, monthly, or even weekly for high-variability environments.
Yes. Supervised learning with PyTorch requires labeled images. If labeling is a challenge, consider semi-supervised or active learning methods.









