

It goes without saying that data is very critical in software development. That’s the reason why developers take no chance whatsoever when it comes to data management.
There are several databases available for efficient management of data. However, in the recent past, DynamoDB has emerged as one of the most popular databases among the developers. But why is that? In this blog, we will provide you with a detailed guide on what Dynamo DB is, what’s its history, design principles, pros & cons, and etc.
We’ll also provide you with a detailed tutorial on how to set up your own DynamoDB database locally. So, without any further ado, let’s begin.
What is DynamoDB?
DynamoDB which is also known as Amazon Dynamo Database or DDB is a NoSQL database service provided by Amazon Web Services. DynamoDB is known for its scalability and latencies.
As per AWS, DynamoDB cuts cost and makes it easy to store and retrieve any amount of data. Furthermore, it can also serve any level of request traffic. The data is stored on solid-state drives which offer high I/O performance along with efficiently handling high-scale requests.
DynamoDB uses a NoSQL database model which is nonrelational. Apart from that, it also allows graphs, documents, columnar among its data model.
A user first stores the data in DynamoDB tables and then interacts with it through PUT and GET queries which are write and read operations respectively.
DynamoDB supports conditional operations and basic CRUD operations. Every DynamoDB query is executed with the help of a primary key which is identified by the user. Each key uniquely identifies each item.
What is the DynamoDB Database?
Apart from the Amazon employees, not many of us know much about the exact nature of DynamoDB. Although, there’s a development version called DynamoDB Local which is written in Java.
We cannot describe what exactly the DynamoDB is as the cloud-native database architecture is proprietary closed-source. However, we can describe how it interacts.
Whenever you set up DynamoDB on AWS, then you don’t allocate set amounts of disk or provision specific servers. Instead, you just provision the throughput, i.e. you define database on the basis of provisioned capacity.
With this, you can manage as to how many kilobytes of traffic or how many transactions you wish to support per second. Users can also specify a service level of write capacity units (WCUs) and read capacity units (RCUs).
Users don’t make DynamoDB API calls directly. Rather, they integrate an AWS SDK into the application which handles the backend communications with the server.
History
The seminal Dynamo white paper (2007) written by the team of Amazon developers served as the inspiration for DynamoDB. This white paper showed quite a contrast to Google’s Bigtable paper which published a year ago in 2006.
Dynamo database was originally intended to use at Amazon as a proprietary solution. Amazon DynamoDB is a customer-oriented Database as a Service (DBaaS) which runs on AWS and Elastic Compute Cloud (EC2) instances.
DynamoDB was released in the year 2012 which was five years after it got inspired by the original white paper.
It’s true that DynamoDB was inspired by the original paper; however, it quickly evolved, all thanks to the advancements in AWS cloud computing and the rapidly changing Big Data landscape.
DynamoDB was designed on the foundation of a core set of distributed systems principles which would result in a highly reliable and ultra-scalable database system.
DynamoDB design principles
If we have a look at the DynamoDB’s design principles then it is required to provide the below attributes:
Managed
It provides ‘as-a-service’ so that the users don’t need to maintain the database.
Scalable
It provisions hardware on the backend automatically in such a way that it’s invisible to the user.
Fast
It supports the predictive levels of provisioned throughput at latencies which are relatively low.
Durable and highly available
It provides multiple availability zones for disaster recovery.
Flexible
It makes it easy for users to start and evolve their database.
Low cost
It is affordable for users when they start.
Read more: AWS Cloud Consulting Services Guide for Successful Execution
DynamoDB Data Storage Format
For managing data, DynamoDB uses b-trees and hashing. DynamoDB does support JSON, but it only utilizes it as a transport format instead of a storage format. Here the implementation of DynamoDB’s data storage format remains proprietary.
Data in DynamoDB is usually exported via bulk downloaded into CSV files through AWS Glue or via streaming technologies. However, the exact nature of data on disk remains hidden from the DybamoDB’s end users.
DynamoDB Data Model
DynamoDB is a key-value store database which uses documented-oriented JSON data model. In this, the Data is indexed with the help of a primary key composed of a sort key and partition key. There is no predefined schema to data in the table as each partition can be quite different from others.
Unlike many of the traditional SQL systems where you can create data models long before knowing how the data will be analysed, with DynamoDB, the data should be modelled based on the various types of queries that you seek to run.
Architecture for data distribution
Amazon Web Services ensure that DynamicDB tables have Availability Zones. This enables you to distribute data across multiple regions in DynamoDB global tables. This feature offers you greater resilience against disaster. However, you must note that with the global tables in place, you must keep your data consistent.
DynamoDB: Pros and Cons
Talking about the pros of DynamoDB, then it’s used when you are required to speedily deploy and prototype a key-value store database which scales to multiple gigabytes and terabytes of information.
This information is often known as “big data” applications. It’s also used for “always-on” use cases with a large volume of transactional requests.
If we talk about the cons, then DynamoDB is an inappropriate choice when it comes to extremely big data sets (petabytes) with high-frequency transactions. Here the cost associated with operating DynamoDB may make it quite prohibitive.
Also, it’s important to note that DynamoDB is a NoSQL database which uses its own JSON-based query API. This means that it should only be used when the data models don’t need normalized data with JOINs across tables.
Read more: AWS Managed Services: A Technical Deep Dive
Local storage vs. Cloud storage: which one to choose?
When it comes to making a choice between local and cloud-based database, then many people find themselves in the state of dilemma. However, developers are choosing local storage over cloud storage for testing and development purpose. There are many reasons as to why developers make this decision. Let’s have a look at them one by one.
Disadvantages of using cloud storage
Highly vulnerable to the security breach
Cloud does come with several protection measures against hackers. However, it’s also true that there’s always a possibility of your sensitive data being breached since nothing on the internet is 100 per cent secure and safe.
No control over your own data
In case of a cloud data storage, a third party can have control over your data. Moreover, you might not be allowed to upload a particular type of data. Also, you must read the fine print since the cloud providers can create terms and conditions of their own.
Requires consistent internet connection
When you’re using cloud storage, then you’ll require a fast and consistent internet connection. Because if you don’t have reliable and fast internet, then you’ll face a lot of problems with cloud storage.
DynamoDB Pricing
DynamoDB cloud storage isn’t free. In fact, you have to literally pay a heavy price for using its services. For an instance, the price for write request units is $1.25 per million units. Similarly, the price for read request units is $ 0.25 per million units.
Apart from that you also have to pay for data storage, backup & storage, DynamoDB Streams, Data transfer, etc. You can view the pricing of all these functions here.
These were some of the demerits of using cloud storage. But you don’t have to worry as you can overcome all these issues by using the local storage. The local storage is ideal when you’re testing your website. Let’s have a look at the advantages of using local storage for testing your website.
Advantages of local storage
Complete control over data
Since the data is stored on the local server, you can have total control over the hardware. However, it also means that either the dedicated employee or you have to manage and maintain the hardware.
Data is easily accessible
With local server, you can have access data right at your fingertips. Moreover, you don’t need to worry about the download and upload speeds for retrieving data.
No need for internet connection
Since you have all the data locally available, you don’t have to worry about your internet connection any more.
It’s absolutely free
One of the biggest advantages of using local storage over cloud storage is that it’s absolutely free. Unlike cloud storage, you don’t have to pay for any requests made.
How to setup DynamoDB locally?
To setup DynamoDB locally, you have to follow certain steps. This might seem complicated at once. But if you carefully follow all the steps then you can set it up without any hassles. So, without any further ado, let’s begin.
Downloading Zip File
The first step is to download the zip file. To download the zip file, you have to visit here and select your region accordingly. Once the zip file is downloaded, then you have to extract its contents.
Loading up
After the completion of the extraction, you have to find the location where a file named “DynamoDBLocal.jar” exists. Once you find its source location, you have to open the terminal in the same folder and run the following command there.
" $ java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDb "
If this command doesn’t work, then you must check whether Java is installed in your device or not. To check, run the following command in the terminal:
“ $ java --version “
If not, please install by referring to the following link:
For UBUNTU: https://ubuntu.com/tutorials/install-jre#1-overview,
The moment you press enter, you might see an error like this:
“ ERROR StatusLogger Log4j2 could not find a logging implementation. Please add log4j-core to the classpath. Using SimpleLogger to log to the console… ”
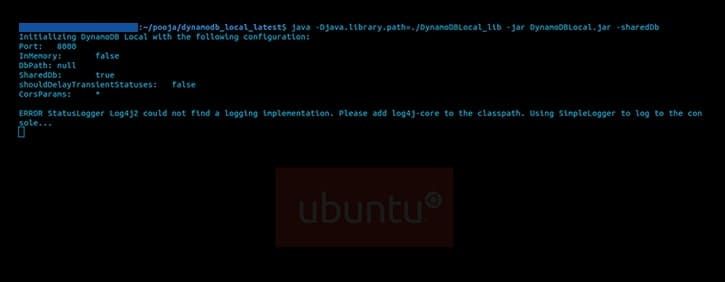
But you don’t need to worry as this error won’t affect the behaviour of the DynamoDB Local as explained in the Amazon’s discussion forum.
AWS CLI Setup:
To check whether the AWS is installed in your machine or not, you have to open the terminal and write the following command:
“ $ aws --version ”
If it’s not installed, then you can setup AWS CLI by referring to the following link:
For UBUNTU: https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html
If it’s already installed, then you can move ahead with the next step.
AWS configuration
The next step is to run "$ aws configure" in the terminal. Here, you have to press enter if you already have the credentials. There can also be a possibility where you don’t have the credentials. In this scenario the following details like:
- AWS Access Key ID
- AWS Secret Access Key
- Default region-name
- Default output format

Will have [none] written in the end. If you face this scenario, then you have to fill the correct credentials.
You must be extra careful in this step as it can change the configuration.
Listing of tables
In order to check the list of tables, you have to enter the following command in the liver server.
" $ aws dynamodb list-tables "
As soon as you enter this command, you’ll see the list of all the tables available on the live server. After this, the next step is to check tables on the local server. For this, you have to enter the following command.
" $ aws dynamodb list-tables --endpoint-url http://localhost:8000 "
As soon as you press enter, you’ll see that there are no tables on the localhost. This means that you have to get all the tables from the live server. And for that, you have to follow few steps which include:
- Exporting live table into JSON format
- Creating a table locally
- Importing JSON file (data) to the locally created table
Let’s have a look at these steps one by one.
Exporting data from table to JSON format
To export data from table to JSON format, you have to write " $ aws dynamodb list-tables " on the terminal.
Here you have to select one table, suppose you chose table_name. Now you have to perform the following command:
" $ aws dynamodb scan --table-name table_name > file_name.json "
With this, you’ll create one JSON file named “file_name.json” all the data of Table_Name table, which was earlier present in the live server.
Now, the next step is to create a new table named table_name for local, where you’ll import the JSON file.
Describing table
Before we create the table locally, we will need information for the same table that is present on the live server.
For now, we have a table_name table that we are working upon. To get the information, let’s write the following on CLI:
" $ aws dynamodb describe-table --table-name table_name "
Here, we need to understand AttributeDefinitions and KeySchema used. To refer them, please follow this link:
Creating Table
Now using the details of KeySchema and AttributeDefinitions, we will create the same table (duplication of table_name) for our local.
Create one project, with the folder structure as:
In file, createTable.js, write down the following code:
With these, we need to install the AWS SDK for JavaScript. For that, run:
npm i aws-sdk
To check if the table is created locally, go to CLI and run:-
" $ aws dynamodb list-tables --endpoint-url http://localhost:8000 "
Inserting data into table:
We’ll use file_name.json to insert the data. Remember the data we have is along with the Attribute Values.
Now to insert the values inside the local table, code:
Contents of Tables:
To get/display the table, type the following command in CLI:
“ $ aws dynamodb scan --table-name table_name --endpoint-url http://localhost:8000 ”
For selection, the command is:
" $ aws dynamodb get-item --table-name table_name --key '{ "id": {"S": "f243fa32-8c5c-4ec1-bb2d-ceb2ec5257a2"}}' --endpoint-url http://localhost:8000 "
where the “–key” parameter is used for selection on which the operation is performed.
Note: Here you have to put your respective id of the record.
Finally, you have your own table which is created locally. This table can be used further as per your preferences.
Conclusion
I hope this article serves as a guide for both laymen and experts who want to deep dive about Dynamo DB. Here we have discussed everything related to Dynamo DB such as its history, design principle, data storage format, data model, architecture, pros & cons.
Not only this, but we also compared the cloud storage and local storage to show why the latter is better. In the end, we also provided with a detailed tutorial on how one can set up Dynamo DB locally. If you want to read more such insightful and educational content then keep reading this space.









